[1] Representer Point Selection for Explaining Deep Neural Networks
Chih-Kuan Yeh, Joon Sik Kim, Ian E.H. Yen, Pradeep Ravikumar
Carnegie Mellon University
这篇文章提出如何解释深度神经网络的预测, 即通过指向训练集中的一组称为代表样本, 用于对给定的测试样本给出预测。
具体而言, 可以将神经网络的激活前的预测分解为训练点激活状态的线性组合, 其权重与代表样本相对应, 从而可以体现出该样本点对网络参数的重要性。
这种做法能够促使对网络进行更深入的理解, 而不仅仅是训练样本的影响: 标签为正的代表样本对应兴奋的训练样本, 同时,标签为负的代表样本对应抑制的训练样本。
这种方法具有比较好的可扩展性, 能够突破影响函数的限制,该方法能够进行实时反馈。
真实的与预测的softmax输出之间的皮尔逊系数图示如下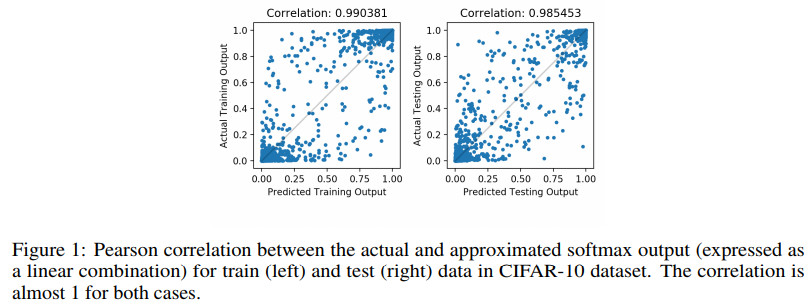
几种方法的效果对比如下
两种方法的耗时对比如下
代码地址
https://github.com/chihkuanyeh/Representer_Point_Selection
[2] Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks
Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Andrea Vedaldi
Momenta, University of Oxford
虽然在卷积神经网络 (Cnn) 中使用自下而上的局部算子与自然图像的一些统计特性非常吻合, 但这种局部算子也可能阻止卷积神经网络捕获上下文中远程的特征交互作用。
在这篇论文中, 作者们提出一种简单的, 轻量级的方法, 该方法能够在卷积神经网络中更好地利用上下文信息。学者们引入一对算子来实现这一点: 第一点即为收集, 它有效地聚合了来自较大空间范围的特征响应, 第二点即为激发这些聚合信息, 将聚合信息重新分配为局部特征。
不管是在所带来的参数数量的增加上还是在额外的计算复杂性方面, 这些算子都很廉价, 可以直接集成到现有架构中, 并且可以提高性能。
在几个数据集上的实验表明, 收集和激发算子带来的好处可以与以很小的成本来增加美国有线电视新闻网的渗透率相当。比如, 融入收集和激发算子的 Resnet-50 能够在 ImageNet 上取得优于其101层所取得的效果, 同时无需额外的可学习参数。作者们还提出了一个参数采集-激发算子对, 这种做法能够带来进一步的性能增益。该文作者将其与最近推出的压缩和激发网络联系起来, 并分析了这些算子对 CNN 特征激活统计所带来的影响。
采集和激发算子图示如下
收集激发算子对ResNet-50的影响如下
不同的收集激发算子的影响对比如下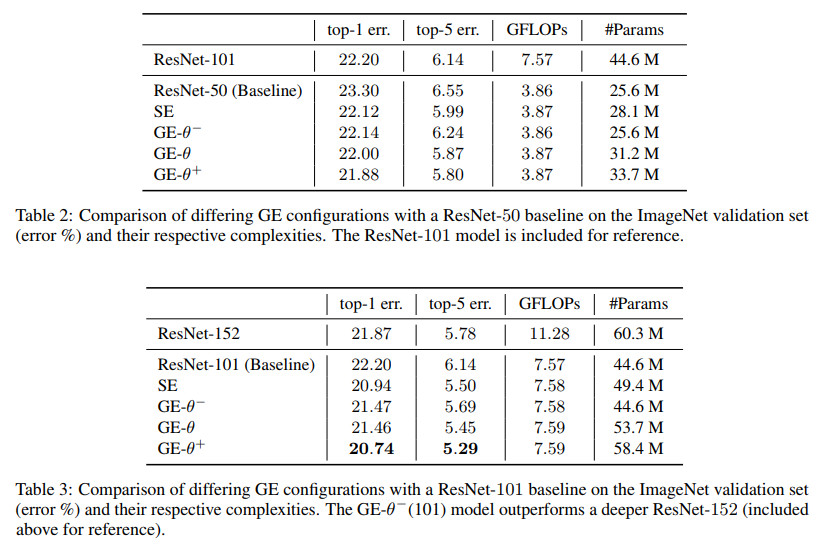
不同的收集激发算子对ShuffleNet的影响如下
其中ShuffleNet对应的论文为
Shufflenet: An extremely efficient convolutional neural network for mobile devices. In CVPR, 2018
代码地址
https://github.com/camel007/Caffe-ShuffleNet
https://github.com/MG2033/ShuffleNet
不同的网络在Cifar-100上的效果对比如下
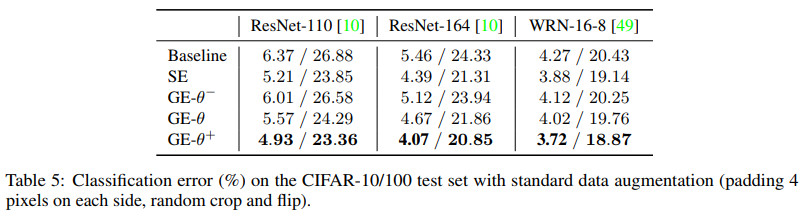
其中WRN-16-8对应的论文为
Wide residual networks. In BMVC, 2016
代码地址
https://github.com/szagoruyko/wide-residual-networks
代码地址
https://github.com/hujie-frank/GENet
[3] Deepcode: Feedback Codes via Deep Learning
Hyeji Kim, Yihan Jiang, Sreeram Kannan, Sewoong Oh, Pramod Viswanath
Samsung AI Centre Cambridge, University of Washington, University of Illinois at Urbana Champaign
在深度数学研究和广泛实际应用中,在统计明确的通道上设计可靠通信的编码非常重要。这篇文章中,通过深度学习提出了一族编码,远远优于过去几十年研究的最佳编码。
本文所考虑的通讯通道是带有反馈的高斯噪声通道,该研究最初由山农提出,反馈机制在理论上能够提升通信的可靠性,但是这样的实用的编码还没有提出。为了突破这种僵局,作者们通过将信息理论洞察与基于递归神经网络的编码器和解码器进行和谐地集成, 进而创造出在可靠性方面比已知代码高出3个数量级的新代码。
这种新代码具有以下几个期望属性:
(1) 能够泛化到更大的块长度;
(2) 可与现有代码相结合;
(3) 能够适应实际中的制约因素。
本文的结果对编码理论产生了更广泛的影响: 即使信道具有清晰的数学模型, 某种深度学习方法, 如果与信道特定的信息理论相结合, 也有可能战胜目前最先进的代码, 虽然这种最先进的代码可能经历了几十年的数学研究而得到。
Deepcodey与其他几种方法的效果对比图示如下
基于简单线性RNN的编码效果对比如下
Deepcode跟其他几种方法的效果对比图示如下
代码地址


文章评论
Itís difficult to find experienced people about this topic, however, you seem like you know what youíre talking about! Thanks