LINE
LINE首次出场于WWW2015,其仍然是基于游走进行的网络嵌入,同时也是一种基于邻域相似假设的方法,只不过与Deepwalk使用DFS构造邻域不同的是,LINE可以看作是一种使用BFS构造邻域的算法。此外,Deepwalk仅能用于无权图,而LINE还可以应用在带权图中。
由于LINE引入了全新的相似度定义,这里需要做必要说明。
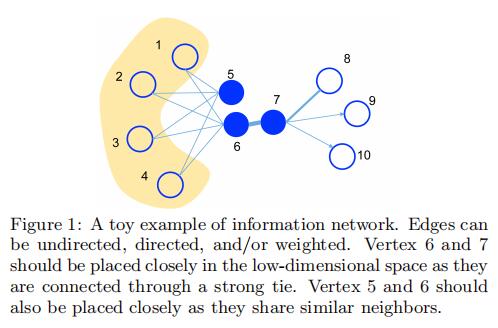
1阶相似度用于描述图中成对节点之间的局部相似度,形式化描述为若u,v之间存在直接连边,则边权w_{uv}即为两个顶点的相似度,若不存在直接连边,则一阶相似度为0。如上图的6和7存在直连边且边权较大,则认为两者相似且1阶相似度很高,而5和6之间不存在直接连边,则两者间1阶相似度为0。
2阶相似度应该是首次由本文提出,我认为是本文主要的贡献点之一。1阶相似度并不足以描述节点间的关联,如上图5和6虽然没有直接连边,但它们有很多相同的邻居节点(1,2,3,4),这也可以说明5和6是相似的,2阶相似度就是用于描述这种关系。形式化定义为,令p_u=(w_{u,1}, ... ,w_{u,|V|})表示顶点u与其他顶点间的一阶相似度,则u和v的2阶相似度可以通过p_u和p_v的相似度表示。若u和v之间不存在相同的邻居节点,则2阶相似度为0。
对于每一条无向边(i, j),定义顶点v_i和v_j之间的联合概率为:
p_1(v_i,v_j)=\frac{1}{1+exp(-\vec{u_i}^T \cdot \vec{u_j})}
其中\vec{u_i}即为顶点v_i的低维表征向量表示,同时定义经验分布:
\hat{p_1}=\frac{w_{ij}}{W}, W=\sum_{(i,j)\in E}w_{ij}
这样优化目标即为:
O_1=d(\hat{p_1}(. , .), p_1(. , .))
其中d(. , .)用于计算两个分布间的距离,常用的衡量指标有KL散度,忽略掉常数项后,优化目标变为:
O_1=-\sum_{(i,j)\in E}w_{ij}log p_1(v_i, v_j)
需要注意的是这里一阶相似度只适用于无向图。
对于每个节点v_i,维护两个embedding向量,一个是该节点本身的表征向量\vec{u_i},一个是该节点作为其他顶点的上下文顶点时的表征向量\vec{u_i}'。
同样地,对于每条边(i, j),定义给定点v_i的情况下,产生上下文邻居节点v_j的概率为:
p_2(v_j|v_i)=\frac{exp(\vec{u_j}'^T \cdot \vec{u_i})}{\sum_{k=1}^{|V|}exp(\vec{u_k}'^T \cdot \vec{u_i})}
其中|V|是节点数或“上下文节点”数目(实际运算结果)。与一阶定义类似,我们有优化目标:
O_2=\sum_{i \in V}\lambda_i d(\hat{p_2}(.|v_i), p_2(.|v_i))
其中\lambda_i为控制节点重要性的因子,可以通过顶点度数、PageRank等方法获得。经验分布定义为:
\hat{p_2}(v_j|v_i)=\frac{w_{ij}}{d_i}
d_i是节点的出度,对于带权图d_i=\sum_{k \in N(i)}w_{ik}。采用KL散度并假设\lambda_i=d_i,忽略常数项,有:
O_2=- \sum_{(i, j)\in E} w_{ij} log p_2(v_j|v_i)
通过学习向量表示\{\vec{u_i}\}和\{\vec{u_i}'\}进行优化,这里有疑问针对\{\vec{u_i}'\},因为在负采样中实际运算设置为与一阶相同的向量。
可见,二阶相似度适用于有向图和无向图。
LINE的模型讲解起来就比较简单了,分别训练一阶相似度和二阶相似度,然后将每个节点训练的两个表征向量结合起来即可。作者提出未来的研究可以针对于联合目标训练函数。
同样地,这里对于二阶相似度中分母部分的运算量很大,因此作者采用了在上一节介绍过的一种优化方法——负采样。具体方法和原理在上节中介绍过,这里放出实际的优化函数供进行比对:
log \sigma(\vec{u_j}'^T \cdot \vec{u_i})+ \sum_{i=1}^K E_{v_n \sim P_n(v)}[log \sigma (- \vec{u_n}'^T \cdot \vec{u_i})]
\sigma(x)为sigmoid函数,K为负边数目,值得注意的是,论文设置了P_n(v) \propto d_v^{3/4},d_v为节点的出度数。
同时,论文提到了一个新的问题,即边采样。
注意到我们的目标函数在log之前还有一个权重系数w_{ij},在使用梯度下降方法优化参数时,w_{ij}会直接乘在梯度上。如果图中的边权方差很大,则很难选择一个合适的学习率。若使用较大的学习率那么对于较大的边权可能会引起梯度爆炸,较小的学习率对于较小的边权则会导致梯度过小。
对于上述问题,如果所有边权相同,那么选择一个合适的学习率会变得容易。这里采用了将带权边拆分为等权边的一种方法,假如一个权重为w的边,则拆分后为w个权重为1的边。这样可以解决学习率选择的问题,但是由于边数的增长,存储的需求也会增加。
另一种方法则是从原始的带权边中进行采样,每条边被采样的概率正比于原始图中边的权重,这样既解决了学习率的问题,又没有带来过多的存储开销。
这里的采样算法使用的是Alias算法,Alias是一种O(1)时间复杂度的离散事件抽样算法,具体不做过多介绍。
论文还提到了一些其他未解决的问题,如:
低度数节点:对于一些顶点由于其邻接点非常少会导致embedding向量的学习不充分,论文提到可以利用邻居的邻居(更高阶邻居)构造样本进行学习,这里也暴露出LINE方法仅考虑一阶和二阶相似性,对高阶信息的利用不足。
新加入节点:对于新加入图的顶点v_i,若该顶点与图中顶点存在边相连,我们只需要固定模型的其他参数,对应其优化两个相似度指标即可:- \sum_{j \in N(i)} w_{ji} log p_1(v_j, v_i)与- \sum_{j \in N(i)} w_{ji} log p_1(v_j| v_i)。如果不存在连边,则需要提供一些额外信息,需要后续的研究。
实验部分


文章评论