续上期,笔记整理系列,重点是笔记。目前主要以社交网络方向为主,不定期更新,干货比较多,内容应该是会越写越多的,想到哪补到哪吧……
上一期总结并归纳了图表征学习,传送门:(整理)社交网络(一)|不如就从图表征说起
本期为图系列的第二章,将开始一步步介绍到图卷积网络(GCN),这章所涉及的文章较多,范围更广,许多精华内容可能只占一部分,并且放到现在价值性难以评估,因此大部分文章略讲或者提供参考链接。且很有意思的是,介绍GCN需要从图神经网络(GNN)的脉络线讲起,而这条脉络线,竟然和上期的图嵌入有密切的关系……
早在深度学习时代来临之前的2005年,图神经网络就已经出现。一般来说,图神经网络旨在通过人工神经网络的方式将图和图上的节点(有时也包含边)映射到一个低维空间,也就是学习图和节点的低维向量表示。这个目标常被称为图嵌入或者图上的表示学习(是不是听上去很熟悉)。反之,图嵌入和图表示学习并不仅仅包含图神经网络这一种方式。
早期的图神经网络采用递归神经网络的方式,利用节点的邻接点和边递归地更新状态,直到到达不动点(后面会介绍)。当我们回头来看这些模型时,会惊奇地发现,它们和我们现在常用的模型已经非常接近了。但是很遗憾,由于模型本身的一些限制(例如,要求状态更新函数是一个压缩映射)和当时算力的不足,这些模型并没有得到足够的重视。
在正式介绍图神经网络之前,需要对CNN中的卷积操作有一定了解,我们知道由于图(Graph)往往并不具备图像那种规整的结构,且图具有节点不均匀性、排列不变性及额外的边属性,因此会很难想象如何在这种图上定义一种卷积操作甚至是图神经网络。需要知道的是,卷积操作的本质是对点的领域聚合,此外,即使是图神经网络,也经历了数十年的发展。因此,在介绍时我将按照普遍理解的两种图神经网络路线来走:谱域图神经网络和空域图神经网络。
谱域图神经网络
图滤波器的设计有多种方式,首先先介绍基于谱的图滤波器。基于谱的图滤波器利用谱图理论来设计谱域中的滤波操作。由于基于谱的图滤波器是在图信号的谱域中设计的,所以在正式进入这节之前,需要了解一些图拉普拉斯矩阵的性质和谱(图谱滤波)的相关知识。
和信号处理的步骤相似,图谱滤波的思想是是调制图信号的频率,使得其中一些频率分量被保留或放大,而一些频率分量被移除或减小。给定一个图信号f\in R^N,首先对其进行傅里叶变换(GFT),然后对变换后的系数进行调制,再在图域(即空间域)中重构该信号。
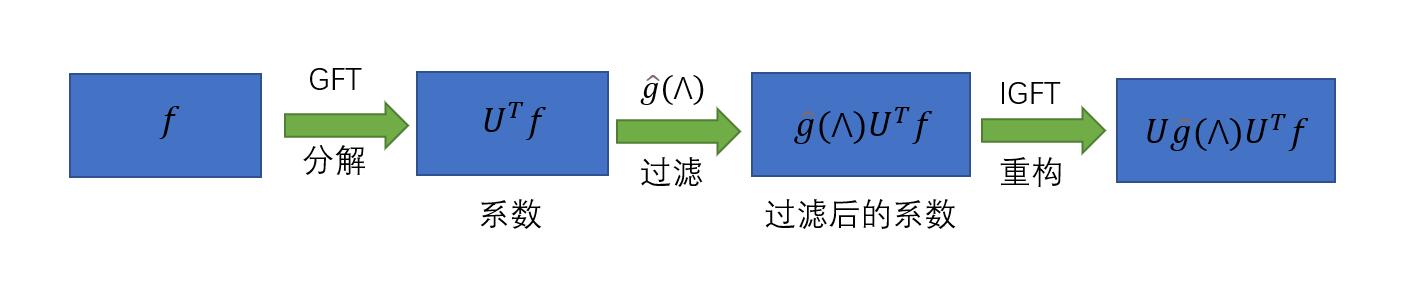
图中的傅里叶变换被定义为:\hat{f}=U^Tf,其中U表示由图g的拉普拉斯矩阵的特征向量组成的矩阵。而拉普拉斯矩阵可以被特征分解为U\Lambda U^T,综合我们可以得到图信号x与一个滤波器g的卷积操作:f'=U\hat{f'}=Ug(\Lambda)U^Tf=g*x,其中g(\Lambda)=diag(\Lambda)是定义的可参数化的卷积核。
将这种图卷积应用到图数据上,并将n维图信号x扩展到n\times d维的图节点属性矩阵X(Node Feature Matrix,此处把Feature翻译成属性是为了和本节中的特征值、特征向量分开来)。具体来说,假设在l层节点状态为X^l,它的维度为n\times d_l,那么更新的节点状态为:x_{j}^{(l+1)}=\sigma (U \sum_{i=1}^{d_l}F_{i,j}^l U^T x_i^l), (j=1,...,d_{l+1})。其中i表示第i列即第i维的图信号或对应的卷积核。如果下一层的节点状态有n\times d_{l+1}维,那么在这一层就有d_l \times d_{l+1}个卷积核。
如果直接把F_{i,j}^l当成可学习的参数,则到这里一个早期谱域图卷积网络就定义完成了,在Bruna 2014这篇文章中,为了解决空间邻域的不规则性,从谱空间进行突破,提出了图上的谱网络。依据图谱论的知识,他们把图的拉普拉斯矩阵进行谱分解,并利用得到的特征值和特征向量在谱空间定义了卷积操作。他们还将此方法扩展到大规模实际数据的分类问题上,并研究了图结构没有预先给出的情况。这样就形成了一个早期的谱域图卷积网络,他们还将方法扩展到大规模实际数据的分类问题上,并研究了图结构没有预先给出的情况。
但是,即使这样仍然存在许多问题。首先得到的网络计算复杂度很高,表现在学习参数与N相关,需要大量内存和数据来拟合,矩阵运算也同样费时;其次卷积算子可能是个稠密矩阵,故输出信号中单元素的计算可能与图中所有节点相关,即在空间域上不是局部化(localized)的,换句话说在空域上没有明确的意义。
为了解决这些问题,Deferrard等人提出了一个新的谱域图卷积网络,实现了快速局部化和低复杂度。由于使用了切比雪夫多项式展开近似,这个网络被称为切比雪夫网络。将卷积核定义为多项式的形式,即\gamma(\Lambda)=\sum_{k=0}^K \theta_k \Lambda^k,其中\theta_k是多项式的参数,这样所需要的参数数量为K+1,并不依赖图中节点数量,这大大降低了参数学习过程的复杂度,并且由于信息在每个节点最多传播K步,这样同时实现了卷积的局部化。并且本文用切比雪夫展开来近似计算卷积核,这意味着优化过程不再需要矩阵分解,大大提高了计算效率,并且切比雪夫多项式的基两两正交,使得学习时受到扰动的鲁棒性更强。最终的表达形如y=\sum_{k=0}^K \theta_k T_k (\tilde{L})x, \tilde{L}=2L/\lambda_{max}-I_n。值得注意的是,由于每一步的迭代函数形式都可以看成对空间域图结构的描述,因此,这种滤波器已经可以被视为基于空间的图滤波器。
在切比雪夫网络的基础上,我们还可以做进一步的简化。当计算一个节点的新表征时,会涉及到该节点的K跳领域,我们可以将多项式卷积核简化到1阶,这样图卷积的公式就近似成了一个关于\tilde{L}的线性函数,可以大大减少计算量。当然,为了还原到原来的多层邻居,我们只需要叠加K层这样的图卷积层,就可以把节点的影响力扩展回去。事实上,叠加多层的设计反而让节点对K阶邻居的依赖变得更弹性,在实验也获得了很好的结果。Kipf与Welling用这种思想设计推导的同时,采用拉普拉斯矩阵对称归一化的版本,由于\lambda_{max} \approx 2,因此可以简化成:y=g_{\theta}(L^{sym})x \approx \theta_0 T_0 (\tilde{L})x+ \theta_1 T_1 (\tilde{L})x = \theta_0 x -\theta_1 D^{-\frac{1}{2}}AD^{-\frac{1}{2}}x,并令\theta=\theta_0=-\theta_1,做进一步简化,可得:y=\theta (I+D^{-\frac{1}{2}}AD^{-\frac{1}{2}})x。再观察括号内的表达式,由于其特征值范围为[0,2],如果我们多次迭代这个操作,可能会造成梯度不稳定和梯度爆炸/消失的问题。因此,我们再做一次归一化,定义\tilde{A}=A+I和\tilde{D_{ii}}=\sum_j \tilde{A_{ij}},归一化后的矩阵变成:\tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}}。
总结一下并将图信号扩展到X\in R^{n\times c},即n个结点c维属性,最终每层的卷积操作为:H=\tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}}X\theta,\theta \in R^{c\times d}是参数矩阵,H\in R^{n \times d}是卷积之后的输出。在实际应用中,通常可以叠加多层图卷积,以H^l表示第l层的节点向量,W^l表示对应层的参数,定义\hat{A}=\tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}},那么每层图卷积可以被正式定义为:
H^{l+1}=f(H^l,A)=\sigma(\hat{A}H^lW^l)
注意此时对于单个节点相当于聚集1阶邻居的信息,因此,这种滤波器也可以看作是一种基于空间的滤波器,在更新节点特征时,只涉及与其直接相连的邻居。可以看到,原本是基于谱域发展的图神经网络,很自然地被推导到结构类似于空域上的图神经网络。这也是理解这篇文章为何重要的原因之一,它连接了两种设计思路的网络,并从晦涩的数学推导式表现到可以用空域理解的结构形式展现出来,并对后世的网络设计产生了深远的影响。
本文最后的网络结构图如下,对了,这篇文章设计的网络有另外一个更加熟悉、响亮的名字:GCN。
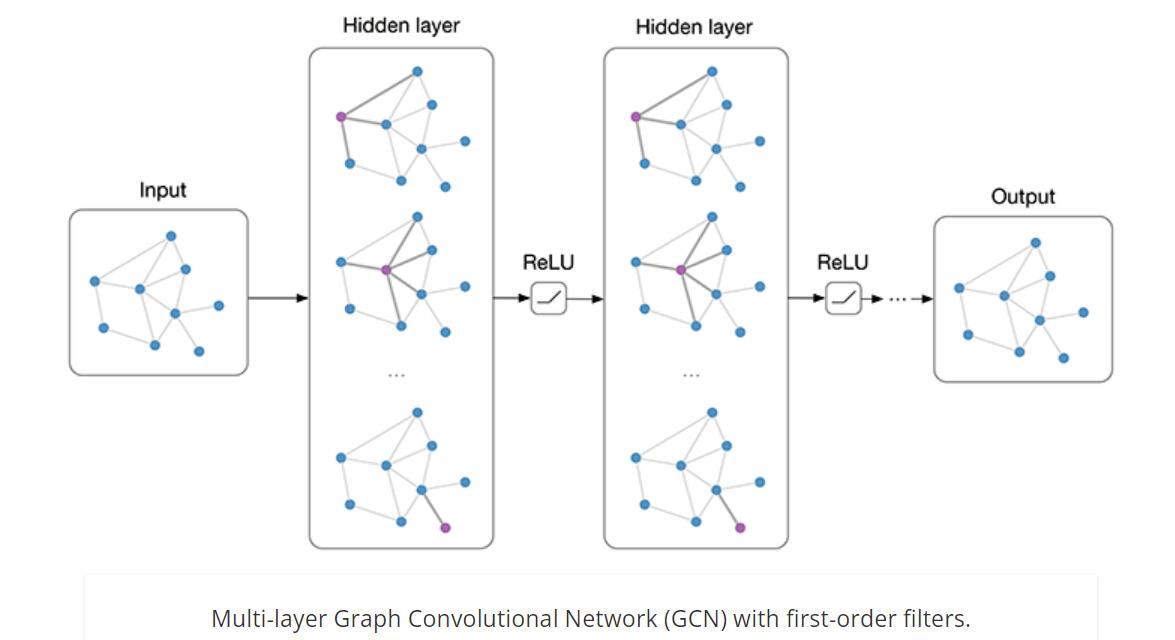
尽管谱域图神经网络有着坚实的理论基础,并且在实际任务中取得了很好的效果,但是也存在明显的局限性。首先,很多谱域图神经网络需要分解拉普拉斯矩阵得到的特征值和特征向量,这是一个复杂度很高的操作。虽然切比雪夫和GCN在做了简化以后已经不需要这一步了,但是它们在计算时仍然需要将全图存入内存,这是很消耗内存的。其次,谱域图神经网络的卷积操作通常作用在图拉普拉斯矩阵的特征值矩阵上,这导致卷积核参数在不同图之间无法共享。
由于谱域图神经网络模型的复杂性一般比较高(除了GCN),局限性也很大,它的后续研究并没有空域图神经网络那么多。但是,理解图谱分析并逐步演变到GCN是有重大意义的,并且对谱域图卷积的研究也一直没有停止过,例如:在图小波网络中通过用小波变换代替傅里叶变换,从而设计出更高级的滤波器(另外图小波变换这里还有个大坑,其相关文章GraphWave是利用谱图小波来做结构上的图嵌入,是Structr2Vec相关比较对象)、反馈环路滤波网络(DFNets)设计了更稳定的滤波器,以及网络结构设计成类DNN的全连接反馈形式(无独有偶,这种设计思想被导师提到了)、LanczosNET对拉普拉斯矩阵做了快速的低秩近似等。
空域图神经网络
出乎意料的是,空域图神经网络出现得更早,并在后期更为流行。它们的核心理念是在空域上直接聚合邻接点的信息。如果把欧几里得空间中的卷积扩展到图上,那么显然一个需要解决的问题是:如何定义一个可以在不同邻居数目的节点上进行的操作,并且保持类似卷积神经网络的权值共享的特性。
最早的GNN的雏形发表于Scarselli 2009年的工作,在这篇文章中细述了神经网络模型的结构组成、计算方法、优化算法、流程实现等等。文中GNN模型通过一个函数\tau(G,n)\in R^m将图G和其中一个顶点n映射到一个m维欧式空间。文章的思想和现在的做法很相似,定义了节点的特征向量和边的特征向量,它的输入如下图所示,包含了节点信息、连边信息、一阶邻居节点的状态和自身信息。对于每个节点,收集其1阶邻居信息并加入神经网络中,这就是最初的GNN雏形。其结构如下:
定义局部转移函数和局部输出函数,具体如下:
x_n=f_w(l_n,l_{co[n]},x_{ne[n]},l_{ne[n]}),o_n=g_w(x_n,l_n)
这种设计非常灵活,而它的基础是巴拿赫(Banach)不动点理论。其核心算法是通过节点的信息传播达到一个收敛的状态,基于此进行预测(由于它的状态更新方式是循环迭代的,所以一般被认为是图循环网络而非图卷积网络)。简单来说,就是如果我们在一个空间上有一个压缩映射,那从某一个初始值开始,一直循环迭代,最终到达唯一的收敛点。
Scarselli等人认为,图上的每个节点有一个隐藏状态,这个状态需要包含它的邻接点的信息,而GNN的目标就是学习这些节点的隐藏状态。那么根据不动点理论,我们只需合理地定义一个压缩映射来循环迭代各个顶点的状态,就可以得到收敛的隐藏状态了。
虽然初代GNN提出了一个很好的概念,但是其基础的不动点理论也造成了它的局限性——节点的状态最终必须吸收周围邻接点的信息并收敛到不动点,这很容易导致层数的叠加,由前面的铺垫很容易想到每个节点最终共享信息,会导致节点过于相似难以区分,即过平滑问题。而这个问题是所有图神经网络都在尽力避免的一个问题,也是目前图神经网络难以或不做深的主要问题之一。此外,GNN只将边作为一种传播手段,并未区分不同边的功能,也没有为边设置独立可学习的参数,意味着无法学习到边的某些特性。幸运的是,这种基于循环神经网络的设计被后人捡了起来,此外感谢谱域方面的重大突破——GCN,基于空域的GNN(后文直接以GNN简称)得以百花齐放。
Li等人沿着早期图神经网络的路线,提出了门控图神经网络(GGNN),门控图神经网络用门控循环单元(GRU)取代了递归神经网络的节点更新方式,从而消除了压缩映射的限制,开始进入支持深度学习时代的优化方式。 之后,在2017年左右,各种图神经网络层出不穷,其中有代表性的几篇文章提出的思想延用至今。例如同年的PATCHY-SAN 首先将节点排序,然后选取固定数量的邻接点仿照卷积神经网络的方式进行图卷积,该方法适用于有向图和无向图,并已经有了结合CV中卷积操作的现代GNN的影子,这是其主要贡献。但用现在的眼光来看,以其为基础可做的工作必然是有限的,更别说还没提供源码。
后面代表性的工作也会像上述这样详略介绍其主要贡献点。在正式开始罗列各种工作之前,我们先从GCN开始回顾一下——GCN是从谱域开始衍生出来的工作,连接了谱域和空域,并促进了GNN的发展。我们现在重新来观察其中一行,也就是一个结点,公式将只有节点的邻接点集合和它自身,这表明图卷积网络每层操作的本质相当于节点属性的扩散,一个节点的状态通过接收邻接点的信息来聚合更新。而这就是典型的空域卷积的做法。这里直接放个扩展结论:图卷积网络还与判断图同构的算法有重大关联(参考1-WL测试),简单来说就是图卷积网络在某种程度上可以看成一个带参数的1-WL算法。而WL测试与图神经网络的表达力直接相关,因此可以认为它实际上是一类图神经网络的表达力的上限。同时这里再放个个人总结:这也解释了在GCN中聚合操作采取不同的聚合函数的话,其不论效果如何一定会有差距,这种差距是由图本身的某种性质决定的。具体相关的证明在后面会提到参考文章。
MPNN。论文主要将图卷积应用到分子的监督学习上,做的是信息传递算法和聚合计算。该文的主要贡献是提出了一个统一的信息传递框架MPNN,并举例了许多已有的文章,如GGNN。原文并没太大阅读价值。
MONET。论文引入了一个通用框架,即混合模型网络。对于对图和流形等非欧数据进行卷积运算。并介绍图滤波操作Mo-Fliter,以节点v_i为例,对于每个邻居v_j \in N(v_i),它引入一个伪坐标表示节点v_j与v_i之间的相关关系。然后用高斯核衡量两个节点之间的关系。这个篇幅并不占原文的主要板块。
到了2017年,在隔壁路线的GCN横空出世后,这给了基于空域的GNN很大的启发,一篇有里程碑式意义的文章出现了——GraphSAGE。
在介绍谱域图卷积网络时,我们提到这类工作的一个局限是不能扩展到其他的图上的。即使是在同一个图上,要测试的点如果不在训练时就加入图结构,我们是没有办法得到它的嵌入表示的。这是早期图神经网络和图嵌入方法都有的类似的问题,我们把这样的框架称为直推式(transductive),即假设要测试的节点和训练节点都在一个图中,并且在训练过程中图结构中的所有节点都已被考虑进去。这样它们就只能得到已经包含在训练过程中的节点的嵌入,对于未知的新加入的节点则束手无策。需要注意的是,GCN虽然是从这种框架中诞生而来,提出时只做半监督、直推式学习,但它是可以改造的,因此认为GCN是跨越在谱域和空域之间。
Hamilton提出了一个归纳式学习的GNN——GraphSAGE。其主要观点是:节点的嵌入可以通过一个共同的聚合邻接点信息的函数得到。在训练时只要得到这个聚合函数,就可以泛化到未知的节点上。而如何定义这个聚合函数,以及用它来定义一个可学习的GNN尤为关键。
GraphSAGE的流程图及算法流程图如下:
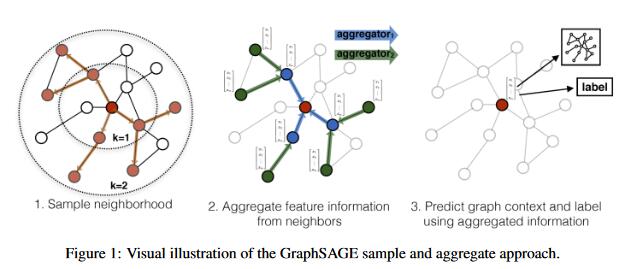

GraphSAGE的SAGE是由Sample(采样)和AggreGatE(聚合)组成的,假设我们有K层网络,在每一层中,节点状态更新的操作被分为两步:先把邻接点的信息全部用一个聚合函数聚合到一起,再与节点本身的状态进行整合和状态更新。在每一层的最后,当所有的节点状态都被更新后,对节点的向量表示进行正则化,缩放到单位长度为1的向量上。这是聚合操作,也很好地概括了这个模型的核心操作。对于采样操作,一方面是为了统一方便批处理,一方面是降低算法复杂度。为了方便批处理,在给定一批要更新的节点后,要先取出它们的K阶邻居节点集合;为了降低计算复杂度,可以只采样固定数量的邻居节点而非所有的。假设每层采样的邻居数为S_l,在实际应用中,一般取K=2,S_1S_2 \leq 500。
图神经网络的一个重要特性是保证不因节点的顺序变化而改变输出,所以所选的聚合函数应该是对称的。原文提供了3种可选择的聚合函数。
1)均值聚合(Mean)。均值聚合即对所有邻接点的每个维度取平均值。这种聚合器和GCN中的滤波器非常相似,在处理节点v_i时,它们都取相邻节点的(加权)平均值作为其新的表示。不同之处在于自身节点v_i的输入表示如何参与计算。在GraphSAGE中这种直接连接到相邻信息的操作类似于skip connection。然而,在GCN-Filter中,自身节点被平等地视为其邻居,也是加权平均过程的一部分。
2)LSTM聚合器。LSTM聚合器将节点v_i的相邻节点N_S(v_i)集合视为一个序列,并利用LSTM模块结构对该序列进行处理。LSTM的最后一个单元的输出用作结果f'_{N_S(v_i)}。但是,邻居之间没有自然的顺序,因此实际采用的时随机排序。显然这种聚合器相比均值聚合有更强的表达力,但它的问题是不对称。
3)池化聚合(Pooling)。池化聚合采用最大池化操作汇总来自相邻节点的信息。在聚合结果之前,先对所有邻接点通过一个全连接层,然后做最大化池化。它的优点是既对称又可训练,其公式可以写成:AGGREGATE_k^{pool}=max(\{\sigma(W_{pool}h_u^k+b), \forall u \in N(v)\})
GraphSAGE的提出为图神经网络的发展带来了非常积极的意义:归纳式学习的方式让图神经网络更容易被泛化;而邻居采样的方式则引领了大规模图学习的潮流。虽然缺乏更理论的分析,但是它在实际应用中的易用性和良好的性能得到了广泛的关注。此外,这种邻接点聚合以及多种聚合函数本身也开拓了空域图神经网络的思路。
到这一步,空域的GNN也开始变得有意思起来了,基于GCN所提出新的归纳式的模型,其全新的想法与模块化的操作给后来一些研究工作者带来了更加开阔的研究设计思路,我们沿着空域这类路看看后面的几篇代表性的文章。这些文章或在之前的工作上加入新机制以完善,或是将新方法重新探索之前的工作。
GAT。应用注意力机制通过赋予输入不同的权重,区分不同元素的重要性,从而抽取更加关键的信息,达到更好的效果。其每层定义如下图。假设我们有N个节点,作为输入的每个节点i的特征是h_i\in R^F,通过这一层更新后的节点特征是h'_i。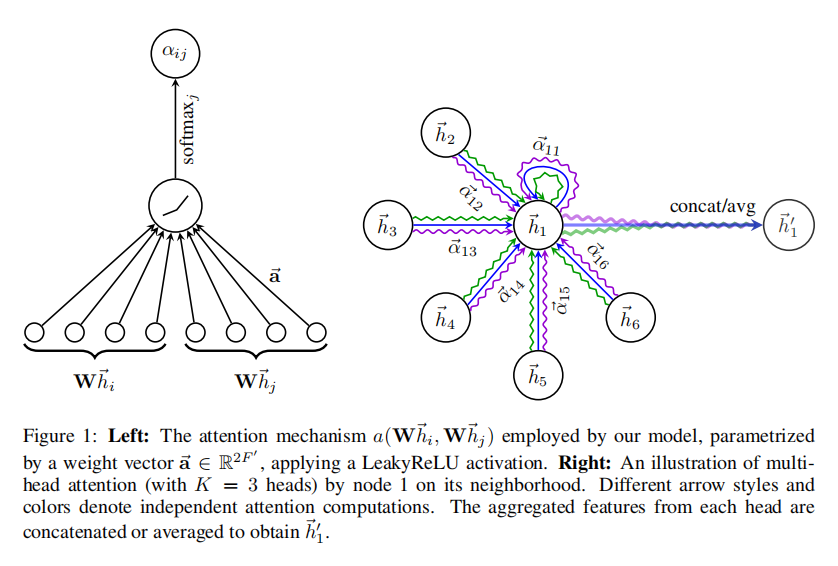
首先,通过一个共享的注意力机制att计算节点间的自注意力:e_{ij}=att(Wh_i, Wh_j)。其中W是一个共享权重,把原来的节点特征从F维转换为F'维,再通过函数att: R^{F'} \to R映射到一个注意力权重。这个权重e_{ij}表示节点j相对于i的重要度。在图注意力网络中,通常选取一个单层前馈神经网络和一个LeakyReLU作为非线性激活函数来计算e_{ij}:e_{ij}=LeakyReLU(a[Wh_i||Wh_j]),其中||表示拼接,a是一个向量参数。
为了保留原来的图结构信息,类似于消息传递网络的方式,我们只计算节点i的邻接点N_i的注意力,再进行归一化和融合。归一化后的注意力权重为:a_{ij}=Softmax_j(e_{ij})=\frac{exp(e_{ij})}{\sum_{k \in N_i}exp(e_{ij})}。更新后的新节点特征为:h'_i=\sigma (\sum_{j \in N_i}a_{ij}Wh_j)。为了稳定注意力机制的学习过程,文献采用了多头注意力机制的研究方法。
GIN。即图同构网络。它分析了图神经网络的表达力问题。对图模型表达力的研究,不仅加深了我们对图神经网络的理解,而且能够帮助我们设计出更好的模型。图同构问题指的是验证两个图在拓扑结构上是否相同,WL测试是一种有效的检验两个图是否同构的近似方法。在原文中,作者详细证明了图神经网络的表达力不会超过WL测试的区分能力,并且给出了得到和测试一样强大的图神经网络——即设计一个单射的聚合函数。出人意料的是,只需要把聚合函数改为最简单的求和函数,就可以提升图神经网络的表达力。这个模型不仅在理论上被证明和WL测试一样强大,且的确在图分类的实验中取得了不错的结果,至今仍广泛运用在图分类任务中。
GNN的应用当然远远不止这些,还有很多可研究的方向,例如解耦的GCN,研究如何解决深度性能下降的问题;异构图神经网络,研究在异构的图数据上设计神经网络模型;图对抗学习,研究图上的对抗攻击,等等。可以说,没有GCN的发展,就没有后续五花八门的运用深度学习思路设计的图神经网络。而令人惊奇的是,GCN的发展是“反着来的”,光是发展到GCN,都走了很长很长的路啊。
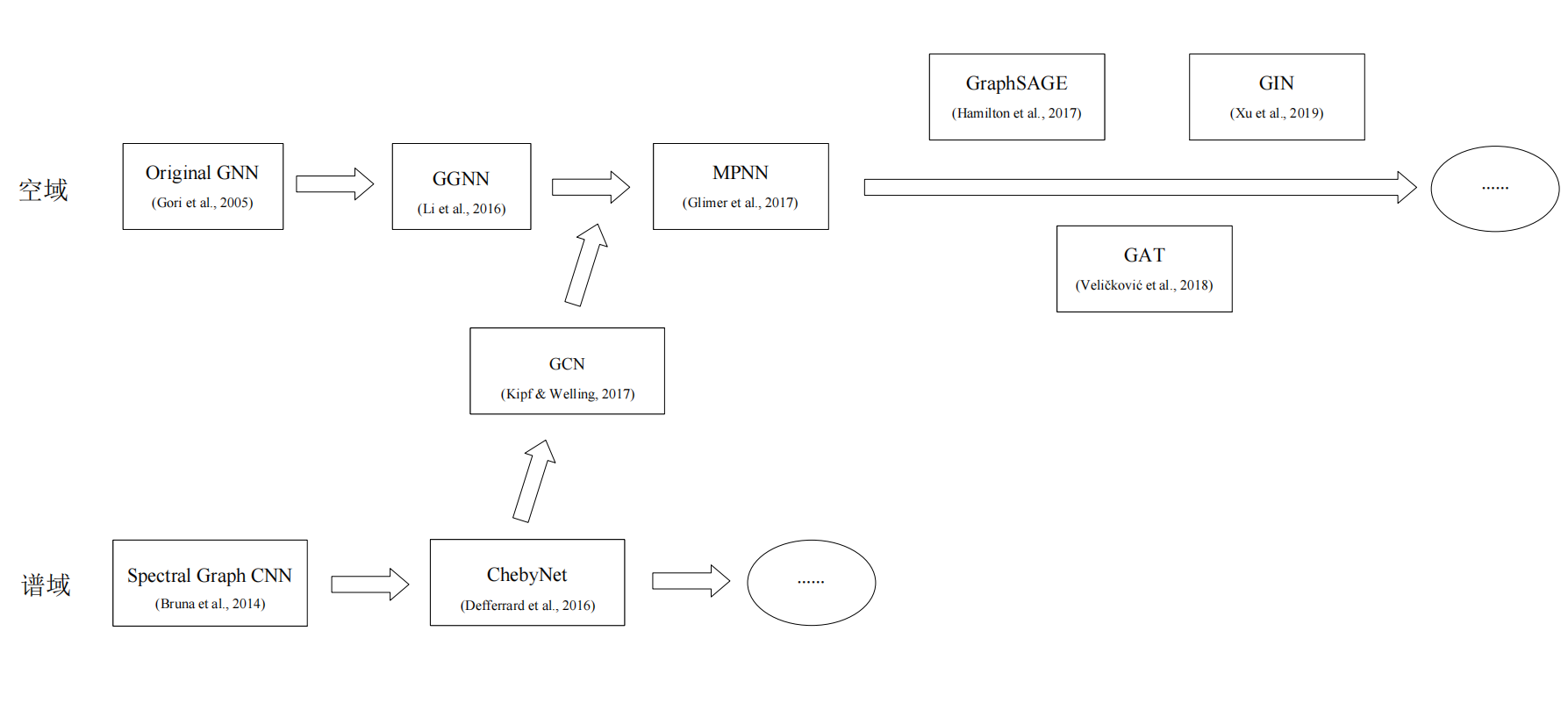 这里总结了早期较为经典的模型和他们的发展线路,当然还有很多文章没有提到,显然,图神经网络的魅力远不止于此!
这里总结了早期较为经典的模型和他们的发展线路,当然还有很多文章没有提到,显然,图神经网络的魅力远不止于此!
写到这里,这期基本把GCN及之前的文章梳理完毕了。虽然很早就已经快总结完了,但碰上了工作只能先搁置在这边(手动/doge)。有很多文章可能只是宕开一笔,这不是我偷懒,而是有些文章的启迪仅仅在于其中的一些小结论,甚至是来自其他方向的。此外,目前两章的工作主要都是在2017年之前,这很自然,因为2017年之后图方向这块的文章和井喷一样(如果有机会写到HGNN,那顶会paper频率可真是人挤人……)。等等,我可没开新坑,也没有要咕咕的意思嗷。


文章评论