上期内容传送门:(原创)推荐&学习记录 | 跟上AI时代论文推荐(DL基础部分)
本期内容为图像分类部分,这一部分内容比较多,毕竟牵扯到CV方向。图像部分有想法可以做得很深,我也只能将个人认为较为重要、基础的内容(个人能力范围以内)做讲解,日后如果有更多内容会补充或者在其他专栏更新。
在开始正式内容之前,有一个贯穿全文的关键词:深度。一般来说,网络层次越深获得的效果越好,但随着深度所带来的问题也是致命与不可避免的,因此你会发现本篇几乎大部分的paper都在以不同的方式改善、解决这个问题。
写在前面的话:
本文受知识产权保护,为避免不必要的麻烦,转载请注明,谢谢!
阅读本文前推荐有一定 “西瓜书”、《深度学习》(Ian Goodfellow)、统计基础更佳。
本文毕竟属于推荐类,确保对所引文章点到为止、突出重点。
截至本文完成,文内所有所推荐内容在paper引用时仍需要注明,不能作为“公理”,直接使用。
图像分类部分
NO.4 Xception
原文:立即下载
Xception是google继Inception后提出的对Inception v3的另一种改进,主要是采用depthwise separable convolution来替换原来Inception v3中的卷积操作。于16年10月挂到arXiv上,中了2017CVPR。截至2019年8月,被引用次数达到800+。想要完整的了解Xception的来龙去脉与原型,需要先从Inception了解起,具体的流程为:
Inception V1 : 《Going deeper with convolutions》
Inception V2 和 Inception V3: 《Rethinking the Inception Architecture for CV》
Inception V4 和 Inception-ResNet:《Inception V4,Inception-ResNet and the impact of Residual Connections on Learning》
Inception背后的想法是通过将其明确地分解为一系列独立地查看通道间相关性和空间上相关性的操作,使这个过程更容易有效。具体来讲,典型的Inception模块首先通过一组1x1卷积查看通道间相关性,将输入数据映射到比原始输入空间小的3到4个独立子空间,然后通过常规的3x3或5x5卷积,映射这些较小三维空间的所有相关性。
Xception中主要采用depthwise separable convolution。什么是depthwise separable convolution?这是mobileNet里面的内容。这里简单介绍下,其实就是将传统的卷积操作分成两步,假设原来是3*3的卷积,那么depthwise separable convolution就是先用M个3*3卷积核一对一卷积输入的M个feature map,不求和,生成M个结果;然后用N个1*1的卷积核正常卷积前面生成的M个结果,求和,最后生成N个结果。
整体结构如下:
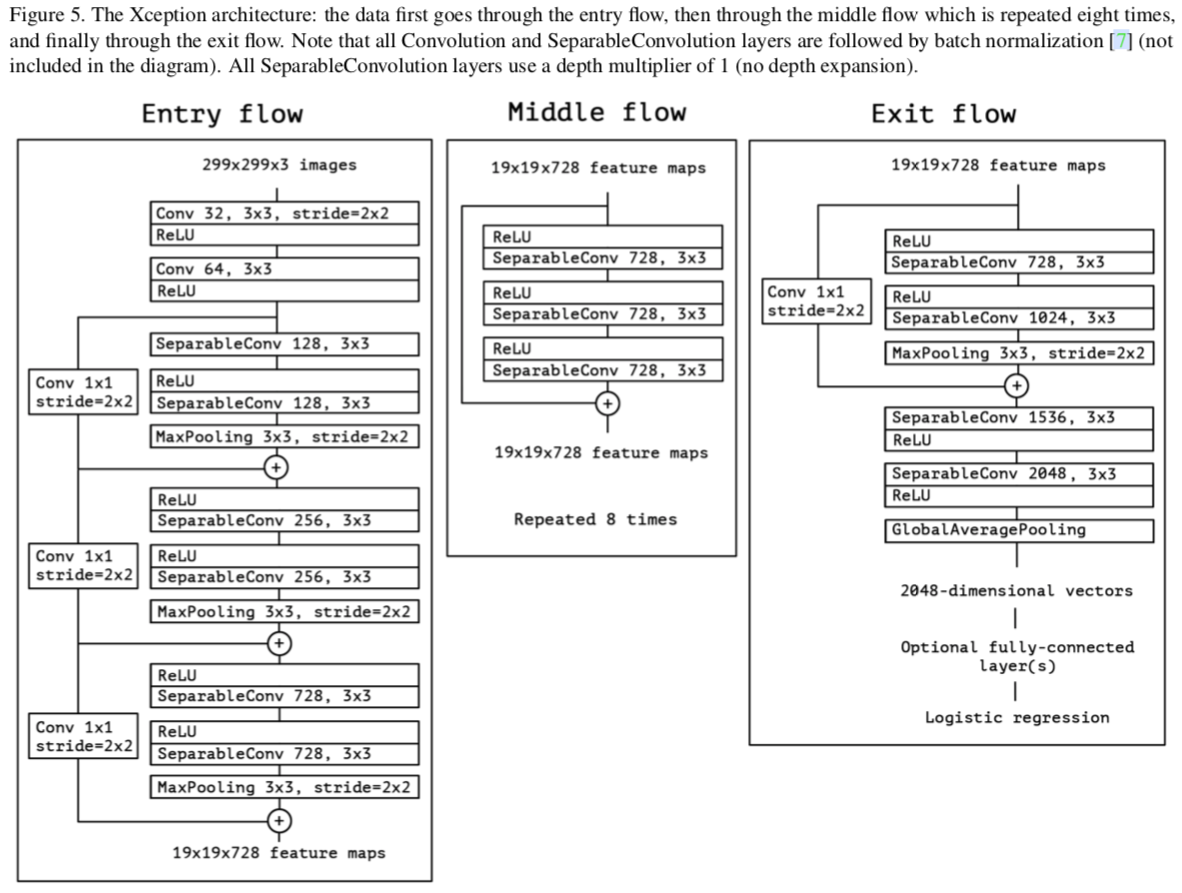
总结一下,Xception不通过增加模型容量,而是通过更有效的参数利用来提升效果的。当然它还是存在一些问题的:例如其底层实现还不是最优的。其本质主要是在之前工作基础上进行改进,原文偏向总结性结论。核心部分比较短,所以在写这一部分时我也很难把握篇幅和深入程度。不过Xception的效果放在当时是很可观的,其提出的问题与解决深度的方法值得借鉴。
小彩蛋环节:
1.本文作者是鼎鼎大名的keras之父,François Chollet,本文由他一人独立完成,都没挂其他人。。不得不说Google还是狠,JFT这么大的数据集自己用不开源,原文训练模型都用了3个月……
2.作者在其twitter上给出了详细架构和代码图……推特学术推特学术(打扰了.jpg)。
NO.5 Resnet
原文:立即下载
来了来了,这篇文章的知名程度足够为其标题加上一个“加粗”。Resnet(残差网络)在如今AI界的传奇那可真的说不完。文章本身现有模型,后完善理论,并于2015年直接斩杀ImageNet三项冠军。知名AI——AlphaGo所采用的一个重要环节就是Resnet……同时不得不感叹这几年技术的飞速发展,Resnet已经逐渐成为比赛中的baseline。Resnet不仅在图像界出名,在其它领域也有很强的表现力。那么,究竟它为什么那么强呢?
Resnet主要解决一个问题:网络层次过深所带来的退化问题。网络层次越深,所带来的梯度消失问题就不可忽视,其优化也越来越难。下图是Resnet经典对比图(论文一出现这图基本就可以反应过来是Resnet):
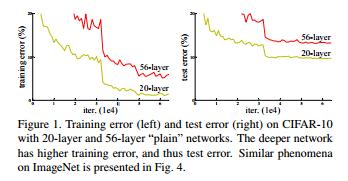
Resnet是怎么解决这个问题的呢?假设我们涉及一个网络层,存在最优化的网络层次,那么往往我们设计的深层次网络是有很多网络层为冗余层的。那么我们希望这些冗余层能够完成恒等映射,保证经过该恒等层的输入和输出完全相同。具体哪些层是恒等层,这个会有网络训练的时候自己判断出来。将原网络的几层改成一个残差块,残差块的具体构造如下图所示:
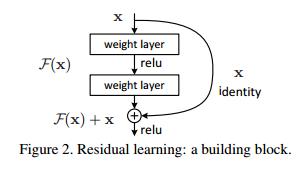
可以看到X是这一层残差块的输入,也称作F(x)为残差,x为输入值,F(X)是经过第一层线性变化并激活后的输出,该图表示在残差网络中,第二层进行线性变化之后激活之前,F(x)加入了这一层输入值X,然后再进行激活后输出。在第二层输出值激活前加入X(如果维度不同,将F(X)调制相同维度),这条路径称作shortcut连接。
结束。
Resnet的介绍就这么简单,但其使用以及详细证明可远远没有这么简单。Resnet将级深的网络实现变为了可能。原文真正做到了大道至简,建议各方向的同学都可以阅读一下,不了解真的是巨大的损失。另外,本文作者之一Kaiming He(何恺明)要特别提一下,上期栏目提到的大神,人生如同开挂,年纪轻轻就取得了卓越的成绩,足以在CV领域留下姓名,个人非常佩服。Resnet这篇文章也算得上我的入门读物之一了,从某种意义上这篇也算我做这一系列的动力,现在来讲解这篇总会有一种特殊的情感……
NO.6 DenseNet
原文:立即下载
看完了Resnet,不得不提到的下一篇就是DenseNet了。DenseNet于Resnet一年后出现,获得CVPR 2017 best paper。DenseNet脱离了加深网络层数(Resnet)和加宽网络结构(Inception)来提升网络性能的定式思维,从特征的角度考虑,通过特征重用和旁路(Bypass)设置,既大幅度减少了网络的参数量,又在一定程度上缓解了梯度消失问题的产生.结合信息流和特征复用的假设,DenseNet当之无愧成为2017年计算机视觉顶会的年度最佳论文。
在提完Resnet后再讲解DenseNet就非常轻松了,DenseNet的结构更像将Resnet“一股脑”地做法:你不是将原始输入传递给输出吗?好,那我把所有的输入都传递给输出,效果不就更好吗?

所以DenseNet的主要模块中每一层的输入为之前所有层的特征图,同时为了避免尺寸带来的影响,中间用卷积层和池化层来处理。
DenseNet有几个明显的优点:
1.减轻了梯度消失问题(vanishing-gradient problem)
2.增强了feature map的传播,利用率也上升了(前面层的feature map直接传给后面,利用更充分了)
3.大大减少了参数量(反常规!!!)
所以有时限制我们思路的真的就是我们自己。把一件事情做到顶、做到绝,未必不会有好的结果。所谓的“暴力”解决问题,可能能带来意想不到的收获?
NO.7 Dilated Convolutions
原文:立即下载
空洞卷积(又叫扩张卷积等,这里由其特性统一称为空洞卷积,2016)所面对的问题是图像分割中像素的密集预测,开发了一种新的卷积网络模块。其系统地聚合多尺度上下文信息而不丢失分辨率。
近年来,有两种处理多尺度推理和全分辨率密集预测的方法
1.持续地从下采用层中反复使用up-convolutions(上卷积、反卷积)恢复损失的分辨率
2.提供多个重新扫描的图像最为输入到网络中,并结合这些多输入的预测
既然加pooling层会损失信息,降低精度,不加pooling层会使感受视野变小,学不到全局特征。那么去掉pooling层,扩大卷积核不就可以了,但是纯粹扩大卷积核势必导致计算上的灾难,此时空洞卷积就诞生了。
经典图如下:
图a,传统的卷积网络,接收域是3x3
图b,使用2-dilated convolution产生的扩张卷积核,接收域是7x7
图c,使用4-dilated convolution产生的扩张卷积核,接收域是15x15
只有图中的9个点的权重不为0,其余都为0
卷积过程如下:
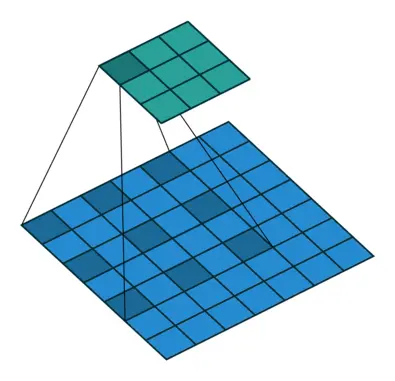
同时,由于实际参与卷积的因子数量没有变,所以卷积的计算量没有变,但是卷积核的尺寸变大,导致特征图中一个特征值对应原来更大的区域,也就是可以获得更大的可是范围。
当然,空洞卷积存在的问题也很明显:
1.因为空洞卷积使得卷积核不连续,损失了连续性信息
2.虽然空洞(膨胀)卷积可以获取更大的视野,但是不利于小物体的分割
空洞卷积本身想法简单,直接且优雅,并取得了相当不错的效果提升,起源于语义分割,思想独特。
NO.8 EfficientNet
原文:立即下载
EfficientNet是谷歌2019最新的论文,这篇文章在有了之前几篇介绍的基础上来讲就很轻松了,本质上属于总结性和介绍性的paper,所以本文推荐篇幅也比较短。全文对目前分类网络的优化提出更加泛化的思想,认为目前常用的加宽网络、加深网络和增加分辨率这3种常用的提升网络指标的方式之间不应该是相互独立的。因此提出了compound model scaling算法,通过综合优化网络宽度、网络深度和分辨率达到指标提升的目的,能够达到准确率指标和现有分类网络相似的情况下,大大减少模型参数量和计算量。
全文实验步骤十分严谨,类似对照试验,控制其他变量对单一变量做研究,并且提出了三种结论(这里不做细表)和普适性的公式。目前已经在图像分类界已经取得了非常好的效果,总结了前人的优秀成果。代码开源,推荐阅读。
NO.9 Grad-CAM
原文:立即下载
在正式开始介绍这篇paper之前,首先要提到深度学习领域不可忽视的一个问题:模型的可解释性问题。在当前深度学习的领域,有一个非常不好的风气:一切以经验论,好用就行,不问为什么,很少深究问题背后的深层次原因。这对长远的研究、学习来讲,会埋下严重的祸患。这也是为什么我在介绍和推荐文章时更偏向和鼓励一些“底层”、“数学”类内容。
Grad-CAM所涉及到的CNN可视化,想要具体了解其来龙去脉则和推荐另外两篇文章(对又是三部曲):
《Visualizing and Understanding Convolutional Networks》
《Learning Deep Features for Discriminative Localization》
第一篇(《Visualizing and Understanding Convolutional Networks》)首次提到了可视化这个问题,并由两个“灵魂拷问”引出:Why CNN perform so well? How CNN might be improved? 文章提到了两种CNN可视化方法:反卷积(采用Conv+ReLU+maxpooling网络)以及导向反向传播(guided-backpropagation),同时这篇文章还总结了反向传播,反卷积和导向反向传播。第二篇(《Learning Deep Features for Discriminative Localization》)则重新审视了global average pooling(GAP)并代替全连接层,同时用class activation mapping(CAM)产生CAM图(一种“热力”图,展现我们的决策区域)。
Grad-CAM则在CAM的基础上进行修改。CAM足够优秀但有时必须修改原网络结构,而Grad-CAM解决了这个问题。Grad-CAM的基本思路和CAM是一致的,也是通过得到每对特征图对应的权重,最后求一个加权和。但是它与CAM的主要区别在于求权重的过程。CAM通过替换全连接层为GAP层,重新训练得到权重,而Grad-CAM另辟蹊径,用梯度的全局平均来计算权重。事实上,经过严格的数学推导,Grad-CAM与CAM计算出来的权重是等价的。当然,Grad-CAM的神奇之处还不仅仅局限在对图片分类的解释上,任何与图像相关的深度学习任务,只要用到了CNN,就可以用Grad-CAM进行解释。
Grad-CAM整体结构如下: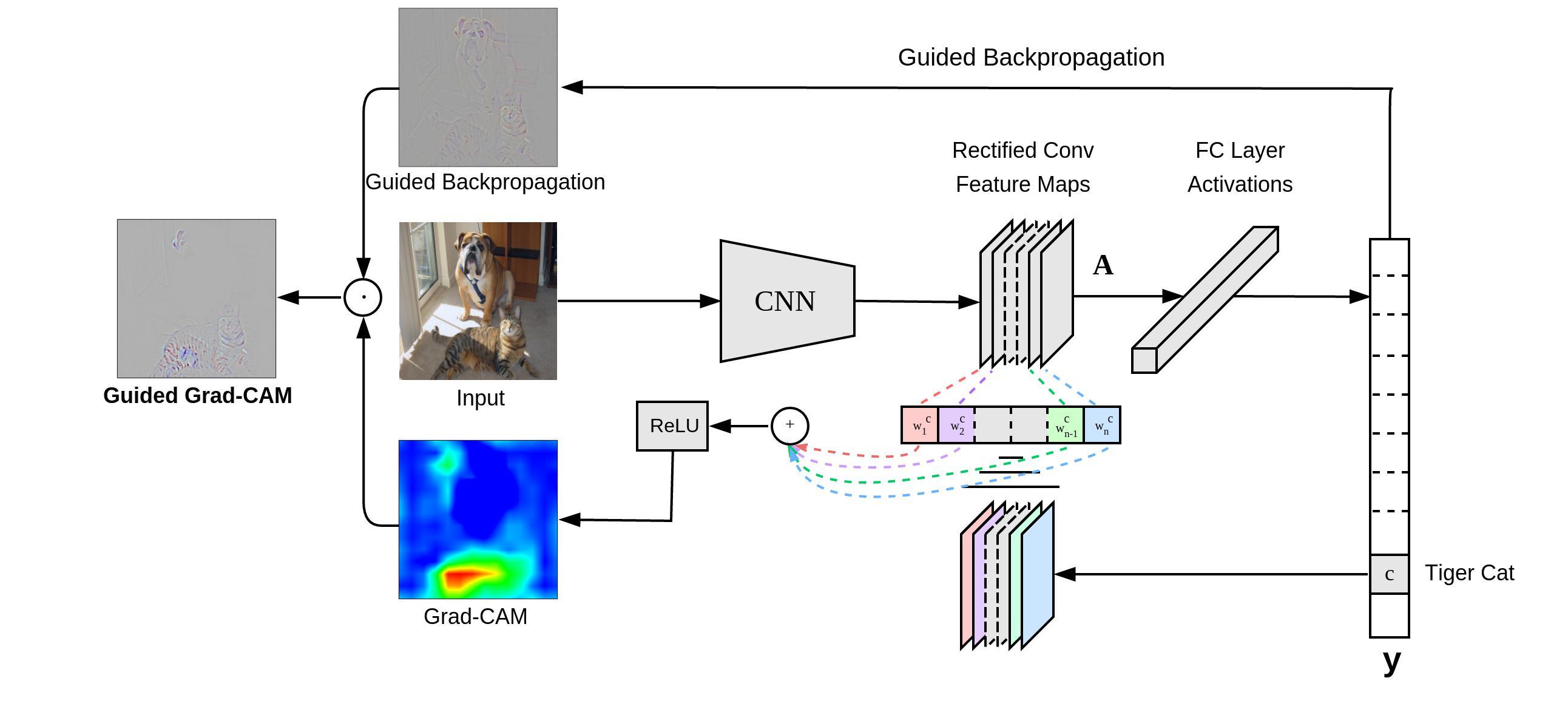
本期的几篇关于图像分类重要的文章就介绍到这里,关于模型效果可以参考Do Better ImageNet Models Transfer Better? 这篇文章,从实验角度证明了ImageNet出身的模型具有普适性。文章本身属于总结实验类,这里不做推荐。
下一期将回归神经元。图像部分内容太庞大了,即使是图像分类也还是有许多没见过的想法,工作量还是有点大的。还是以学习积累为主,不定期更新,敬请期待。
NIPS2018专栏:NIPS2018


文章评论