[1] Task-Driven Convolutional Recurrent Models of the Visual System
Aran Nayebi, Daniel Bear, Jonas Kubilius, Kohitij Kar, Surya Ganguli, David Sussillo, James J. DiCarlo, and Daniel L. K. Yamins
Stanford University, MIT, KU Leuven, Google, Inc., Wu Tsai Neurosciences Institute
目前,前向卷积神经网络在物体分类任务中的效果非常好。生物视觉系统中有两种普遍存在的结构特征,皮质区局部循环以及下游区到上游区的长范围反馈,这两种特征并没有体现在典型的卷积神经网络中。
这篇文章主要讨论如何利用循环来提高分类性能。标准形式的循环,比如RNNs和lstms,跟深层cnn融合用于imagenet上并不能取得较好的效果。通过融入两种结构特征,避开(bypassing) 及门限(gating),可以显著提升准确率。作者们将这些思路利用自动搜索的方式扩展到几千种模型结构,结果表明,新颖的局部循环单元和长距离反馈连接有助于提升物体识别的性能。
模型结构示例如下
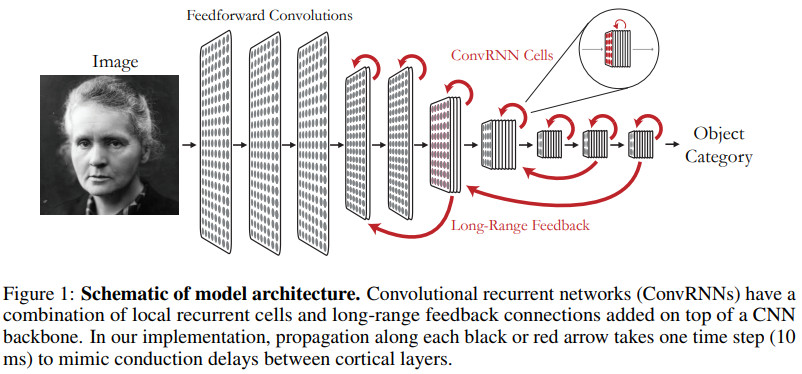
几种结构及效果对比如下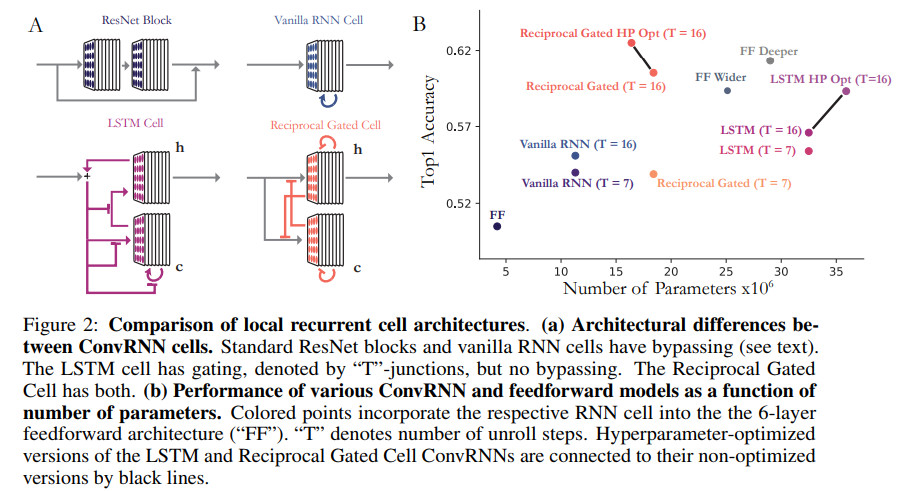
超参数及搜索结构如下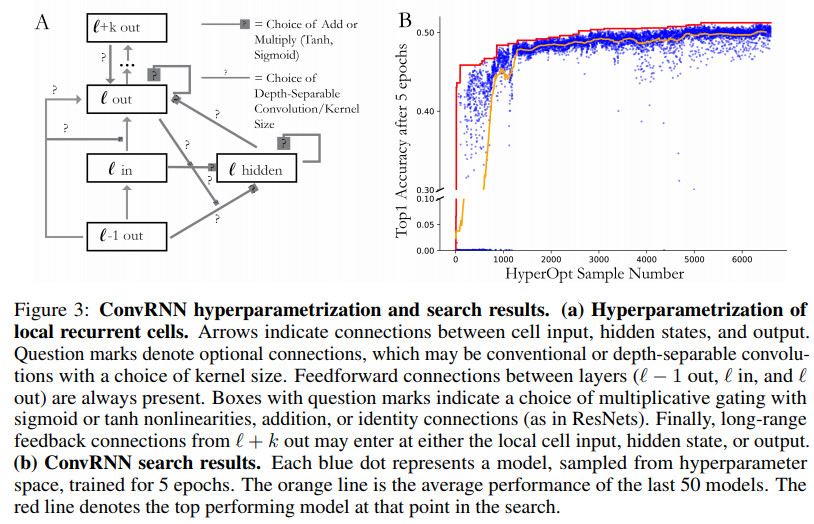
代码地址
https://github.com/neuroailab/tnn
[2] Semi-supervised Deep Kernel Learning: Regression with Unlabeled Data by Minimizing Predictive Variance
Neal Jean, Sang Michael Xie, Stefano Ermon
Stanford University
训练深度学习模型通常需要大量的标注数据。但是,在实际情况中,获取这些有标注的数据通常比较昂贵,甚至有些时候几乎不可能获取。
为解决上述问题,作者们提出了半监督深层核学习(SSDKL)。这是一种基于后验正则框架的半监督回归模型,目标在于最小化预测方差。SSDKL结合了神经网络的分层表示学习和高斯过程的概率建模能力。
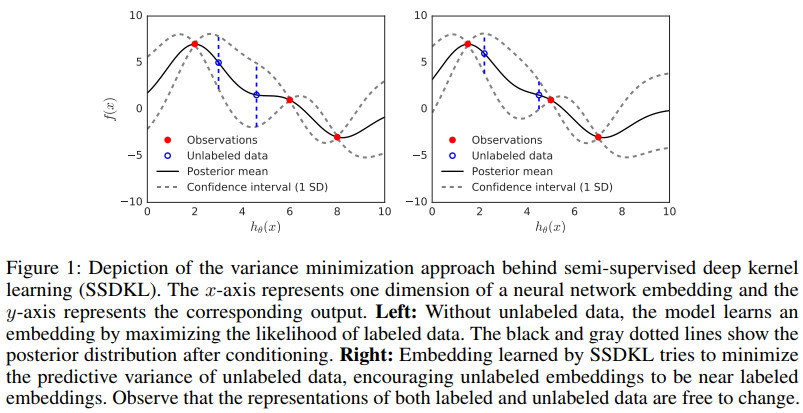
SSDKL效果示例如下
在几个数据集上多种方法所带来的rmse降低的幅度对比如下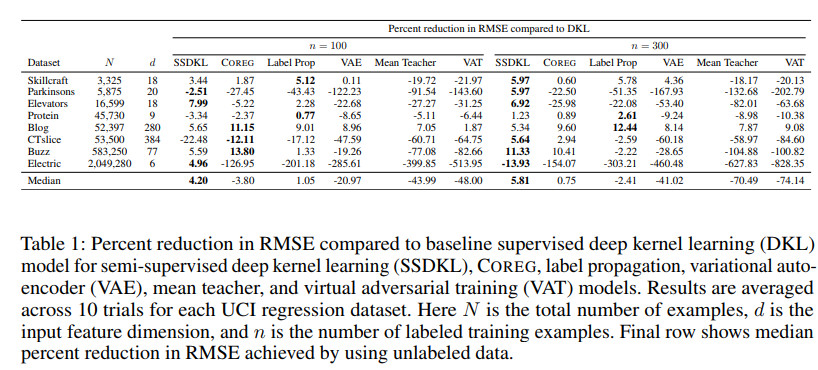
几种方法的效果随带标签样本数的变化对比如下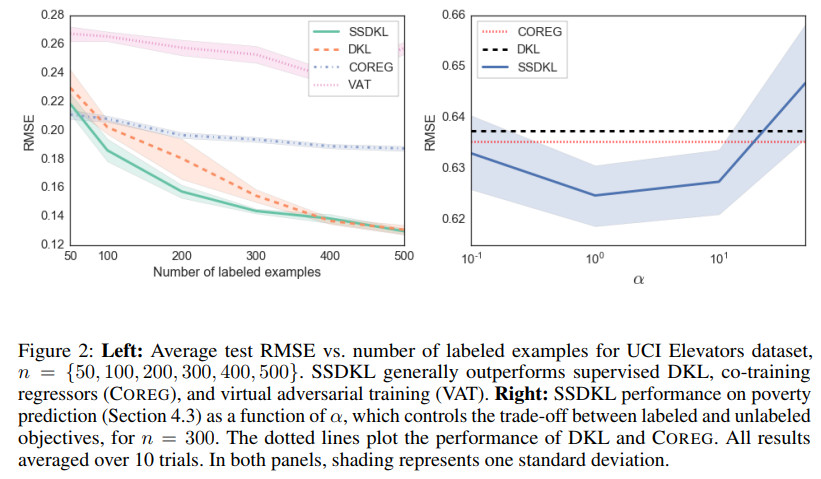
二维嵌入效果对比如下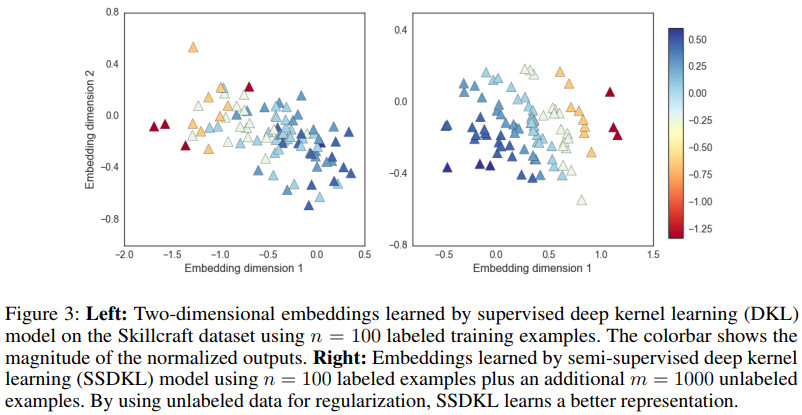
代码地址
https://github.com/ermongroup/ssdkl
[3] Generalizing to Unseen Domains via Adversarial Data Augmentation
Riccardo Volpi, Hongseok Namkoong, Ozan Sener, John Duchi, Vittorio Murino, Silvio Savarese
Istituto Italiano di Tecnologia, Stanford University, Intel Labs
这篇文章主要讨论一种特殊的学习模型,即如何较好地泛化到不同的未知域。只利用单个源域分布的数据来训练,针对基于当前模型扩展数据集比较难的情形,作者们提出一种迭代式过程,利用虚构的目标域样本来扩展数据集。
这种迭代式框架是一种自适应的数据增广方法,在每次迭代中都添加对抗样本。对于softmax损失函数,该方法是一种依赖于数据的正则方法,跟经典的正则方法(比如l1或者l2正则)不同。在数字识别和语义分割任务中,作者们提出的方法取得了很好的效果。
对抗式数据增广算法伪代码如下

代码地址


文章评论