[1] RenderNet: A deep convolutional network for differentiable rendering from 3D shapes
Thu Nguyen-Phuoc, Chuan Li, Stephen Balaban, Yong-Liang Yang
University of Bath, Lambda Labs
传统的计算机图形渲染管道能够将3D形状程序性地生成2D图像,同时具有高性能。由于离散操作(例如可见性计算)会导致不可区分性,这种现象使得难以将渲染参数和所得到的图像精确地关联起来,进而给逆渲染任务带来重大挑战。
最近可微渲染相关的工作通过两种方法来实现可微分性,即通过为不可微操作设计替代梯度或者通过近似但可微分的渲染器。但是,这些方法在处理遮挡情况时仍然具有一定的限制性,仅限于特定的渲染效果。
作者们提出RenderNet,一种可微分的渲染卷积网络,该网络具有一个新颖的投影单元,能够将3D形状渲染成2D图像。在该网络中,空间遮挡和阴影计算能够自动编码。
实验表明,RenderNet能够学到不同的着色器,并且可以在逆渲染任务中根据单个图像估计形状,姿势,光照和纹理。
这篇文章的主要贡献可以总结为以下三点
网络结构图示如下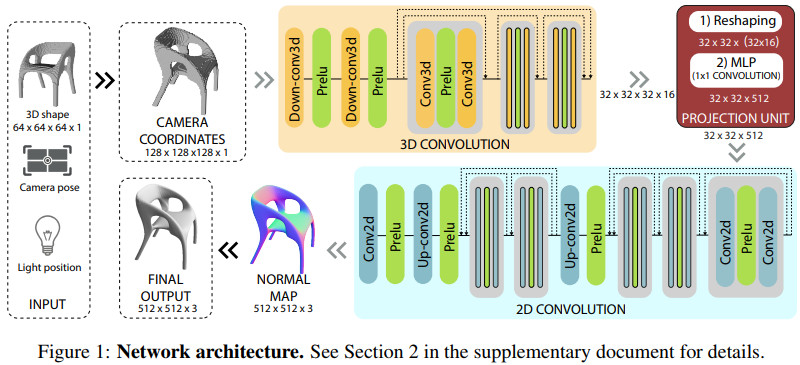
几种方法的效果对比及图示如下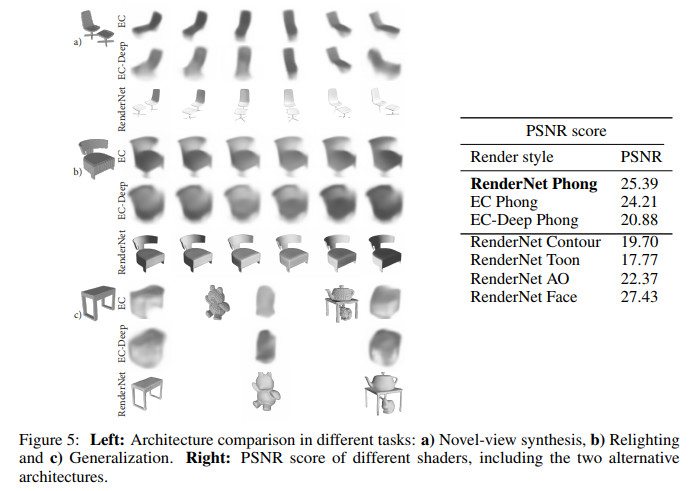
代码地址
https://github.com/thunguyenphuoc/RenderNet
[2] Hamiltonian Variational Auto-Encoder
Anthony L. Caterini, Arnaud Doucet, Dino Sejdinovic
University of Oxford, Alan Turing Institute for Data Science
变分自动编码器(VAE)在潜变量模型中进行推理和学习任务中已经非常流行,这种编码器可以利用神经网络的丰富表征能力来得到潜在变量后验分布的灵活近似,该编码器还可以得到紧致的证据下限(ELBOs)。
这种方法跟随机变分推断结合能够得到一种扩展到大型数据集的方法。但是,为使该方法实际有效,有必要获得ELBO的低方差无偏估计,还需要得到关于感兴趣参数的梯度。
虽然部分学者建议使用马尔可夫链蒙特卡罗(MCMC)方法(例如哈密顿蒙特卡罗(HMC))完成上述目标,但是这些方法需要指定对性能具有很大影响的反向核。另外,对于大多数MCMC内核,ELBO的无偏估计通常不适用于重新参数化技巧。
作者们展示了如何选择最佳的反向核,通过建立哈密顿重要性采样(HIS)得到一种方案,该方案使用重新参数化技巧得到ELBO的低方差无偏估计及其梯度。作者们进而提出了哈密顿变分自编码(HVAE)。
该方法可以解释为目标通知的标准化流程,在本文中,仅需要对每次迭代中的采样似然和平凡雅可比计算的梯度进行一些评估。
哈密顿ELBO算法伪代码如下
其中(5)式为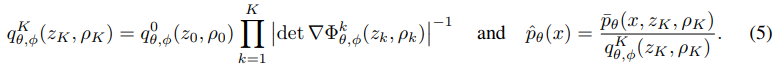
(7) (8) (9)为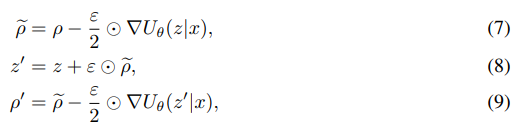
哈密顿VAE算法伪代码如下
几种方法的比较如下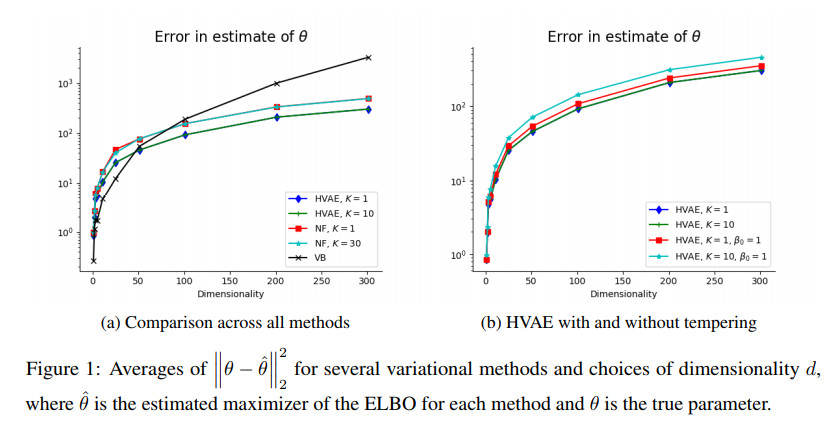
不同参数下的效果对比如下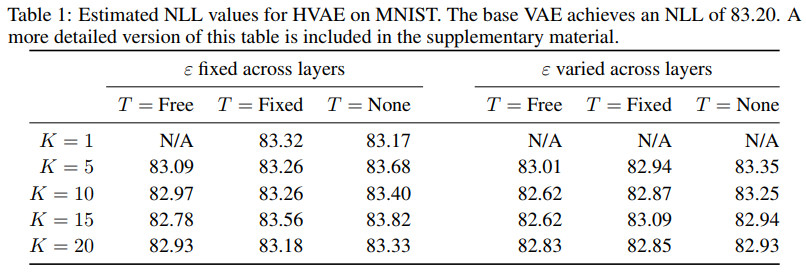
代码地址
https://github.com/anthonycaterini/hvae-nips
[3] Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels
Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor W. Tsang, Masashi Sugiyama
University of Technology Sydney, RIKEN, 4Paradigm Inc., Stanford University, University of Tokyo
带有噪声标签的深度学习具有一定的挑战性,因为深度模型的容量非常高,以至于这些模型能够在训练期间记住这些噪声标签。
尽管如此,最近关于深度神经网络记忆效果的研究表明,这些模型首先会记住带有清洁标签的训练数据,然后记住带有噪声标签的训练数据。因此,在本文中,作者们提出了一种新的深度学习范式,称为“Co-teaching”,用于处理噪声标签。
这种范式中,同时训练两个深度神经网络,并让这俩网络在每个小批量中相互教授:首先,每个网络前馈所有数据并选择一些带有可能干净的标签的数据; 其次,两个网络相互通信,每个小批量的哪些数据应该用于训练; 最后,每个网络反向传播其对等网络所选择的数据并自行更新。
在MNIST,CIFAR-10和CIFAR-100三个数据集的噪声版本上的实证结果表明,在训练深度模型的稳健性方面,“Co-teaching”远远优于最先进的方法。
几种方法的对比图示如下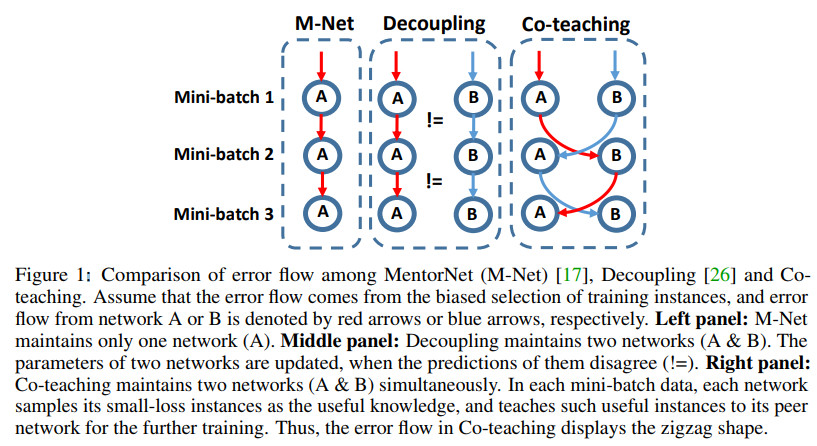
其中Mentornet对应的论文为
Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels. ICML, 2018
Decoupling对应的论文为
Decoupling" when to update" from" how to update". NIPS, 2017
Co-teaching算法伪代码如下
数据集统计如下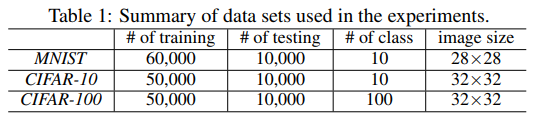
不同噪声类型的转换矩阵示例如下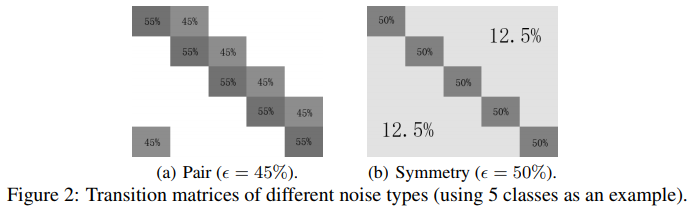
几种方法在不同情形下的对比如下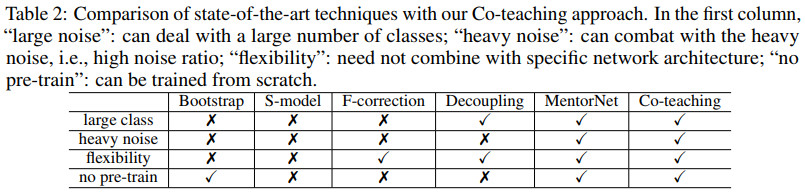
三个数据集上的CNN结构如下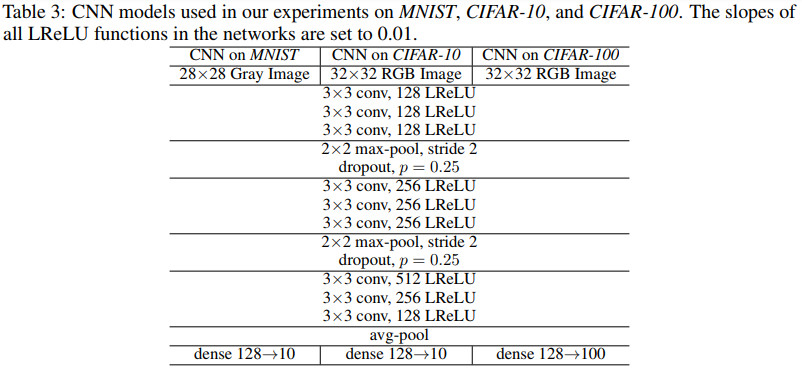
几种方法在MNIST上的测试准确率对比如下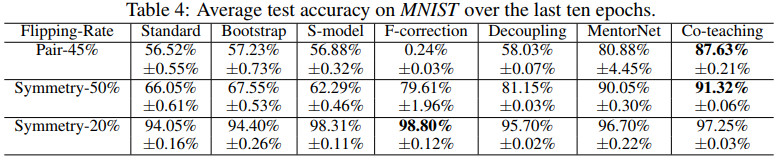
几种方法在MNIST上的测试准确率随迭代次数变化的对比如下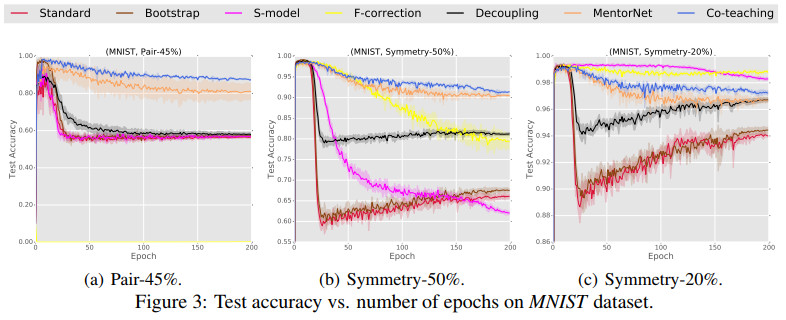
几种方法在MNIST上的标签精准率随迭代次数变化的对比如下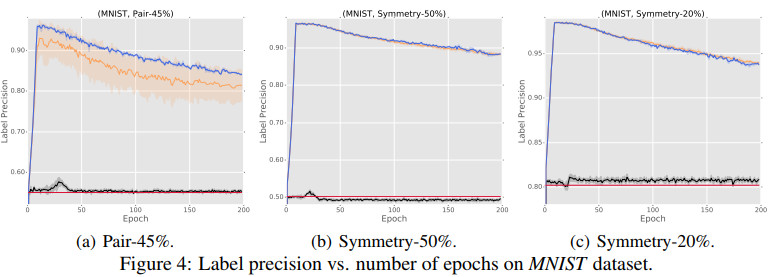
几种方法在CIFAR-10上的测试准确率对比如下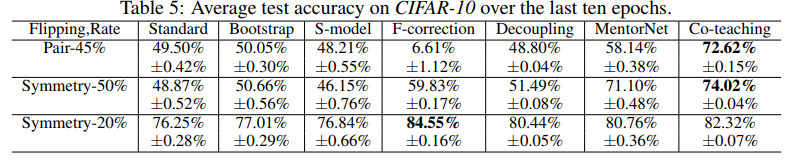
几种方法在CIFAR-10上的测试准确率/标签精准率随迭代次数变化的对比如下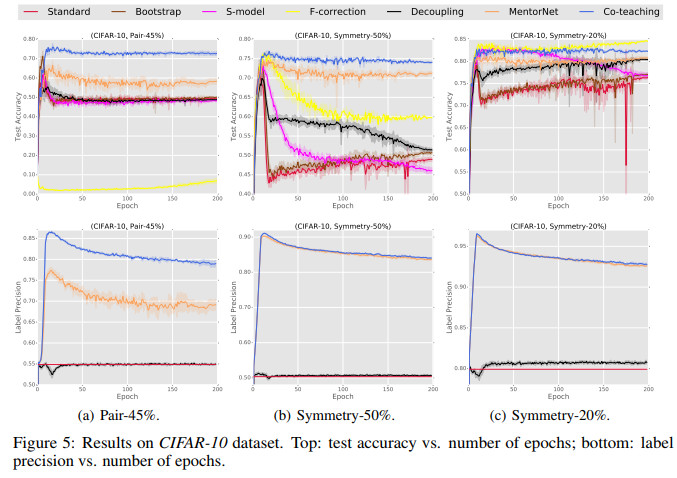
几种方法在CIFAR-100上的测试准确率对比如下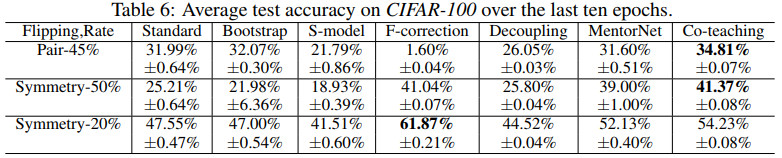
几种方法在CIFAR-100上的测试准确率/标签精准率随迭代次数变化的对比如下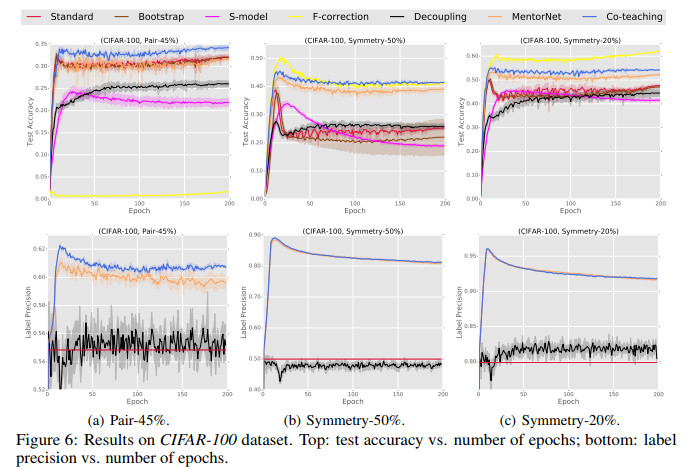
不同参数在MNIST上的测试准确率对比如下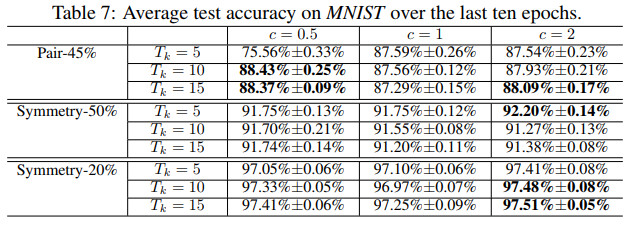

代码地址


文章评论