[1] 3D Steerable CNNs: Learning Rotationally Equivariant Features in Volumetric Data
Maurice Weiler, Mario Geiger, Max Welling, Wouter Boomsma, Taco Cohen
University of Amsterdam, EPFL, University of Copenhagen, Qualcomm AI Research
这篇文章提出一种新型卷积网络,该网络与刚体运动等价。该模型使用三维欧几里得空间上的标量、矢量和张量场来表示数据,同时使用等变量卷积来得到这些表示之间的映射。
这些SE(3)等变量卷积是基于内核的,这些内核是由完备可引导内核基的线性组合得到的,本文对此进行了分析性推导。本文证明了等变量卷积是三维空间中场之间最一般的等数线性映射。
实验结果表明,3D可引导CNN在氨基酸倾向预测和蛋白质结构分类问题上效果可观,两者均具有固有的SE(3)对称性。
几种方法的效果对比如下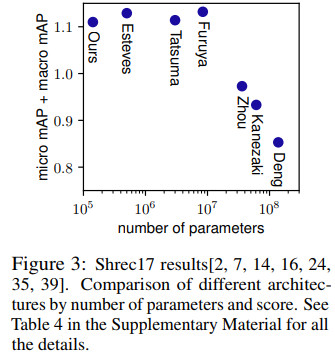
其中2对应的论文为
Gift: A real-time and scalable 3d shape search engine, CVPR 2016
7对应的论文为
Spherical CNNs,ICLR 2018
14对应的论文为
3D object classification and retrieval with Spherical CNNs,2017
16对应的论文为
Deep aggregation of local 3d geometric features for 3d model retrieval, BMVC 2016
24对应的论文为
Rotationnet: Joint object categorization and pose estimation using multiviews from unsupervised viewpoints, 2018
代码地址
https://github.com/kanezaki/rotationnet
35对应的论文为
Large-Scale 3D Shape Retrieval from ShapeNet Core55, 2017
39对应的论文为
Multi-fourier spectra descriptor and augmentation with spectral clustering for 3d shape retrieval,2009
准确率随训练集大小变化图如下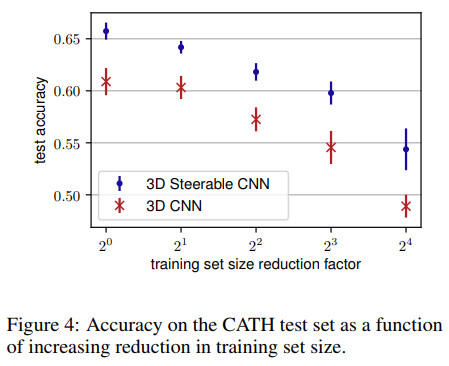
代码地址
https://github.com/mariogeiger/se3cnn
数据集地址
https://github.com/wouterboomsma/cath_datasets
[2] Mesh-TensorFlow: Deep Learning for Supercomputers
Noam Shazeer, Youlong Cheng, Niki Parmar, Dustin Tran, Ashish Vaswani, Penporn Koanantakool, Peter Hawkins, HyoukJoong Lee Mingsheng Hong, Cliff Young, Ryan Sepassi, Blake Hechtman
Google Brain
对数据进行分批,使得数据并行化,在分布式深层神经网络训练策略中占有主流地位,该方法具有通用性,而且能够促成单程序多数据流编程。
然而,数据分批处理存在一些问题,比如由于内存限制无法训练非常大的模型,而且具有高延迟性,另外,批量过小时会导致效率低下。值得高兴的是,这些问题都可以通过比较常用的分布策略(模型并行化)来解决。不幸的是,高效的模型并行算法往往比较复杂,难以发现、描述,并且难以实现,尤其在大型集群上更是如此。
本文提出了 Mesh-TensorFlow,它是一种用于特定类别分布式张量计算的语言。在 Mesh-TensorFlow 中,数据并行性可以看做沿"批处理"维度进行拆分张量和操作,用户可以指定在多维处理器网格上的任意维度拆分,进而得到任意张量维度。
Mesh-TensorFlow 图可以编译为 SPMD 程序,该程序由并行操作与集合通信基元(如 Allreduce)结合。本文利用 Mesh-TensorFlow 实现了Transformer序列到序列模型的另一个高效版本,该版本数据并行、模型也并行。作者们利用 512 个内核的 TPU 网格,训练具有多达 50 亿个参数的Transformer模型,效果超越了 WMT'14 英语-法语翻译任务和 10 亿字语言建模基准的当前最优结果。
同步数据并行算法伪代码如下
不同情况对比如下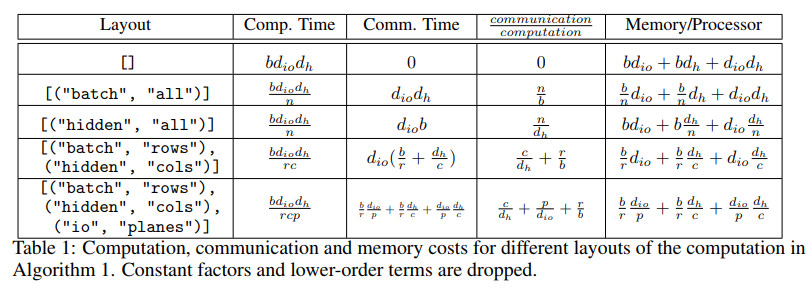
几种方法的效果对比如下
其中[13]对应的论文为
Exploring the Limits of Language Modeling
[15]对应的论文为
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-ofExperts Layer
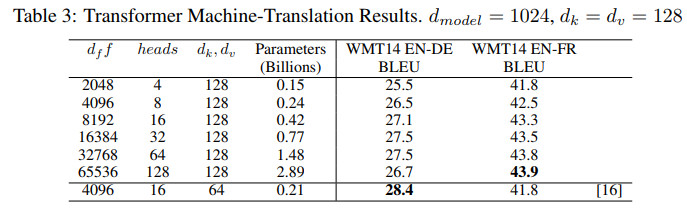
Transformer对应的论文为
Attention Is All You Need
代码地址
https://github.com/jadore801120/attention-is-all-you-need-pytorch
https://github.com/Kyubyong/transformer
代码地址
https://github.com/tensorflow/mesh
[3] Using Trusted Data to Train Deep Networks on Labels Corrupted by Severe Noise
Dan Hendrycks, Mantas Mazeika, Duncan Wilson, Kevin Gimpel
University of California, University of Chicago, Foundational Research Institute, Toyota Technological Institute at Chicago
海量数据集在深度学习中的重要性与日俱增,这使得将噪声标签标记为分类器的关键属性变得十分重要。
标签的噪声源包括自动标签、非专家标签和数据中恶化对抗样本的标签损坏。很多之前的工作都假设标签的来源是不能全部信任的。作者们放宽了此假设,并假定训练数据中的一小部分标签是可信的。这种做法有助于实现大量标签损坏的情况下模型的鲁棒性能得以提升。
此外,通过使用一组带有干净标签的可信数据,可以消除特别严重的标签噪音。作者们利用可信数据,提出了一种损失校正方法,利用可信样本以数据效率的方式减轻标签噪声对深度神经网络分类器的影响。
在计算机视觉和自然语言处理任务中,本文方法在各种标签噪声进行了实验,结果表明该方法明显优于现有方法。
标签污染矩阵如下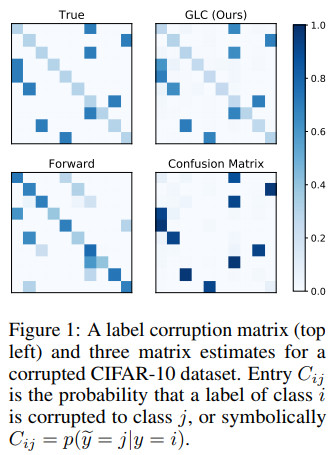
损失校正算法伪代码如下
不同的标签损失程度的误差曲线如下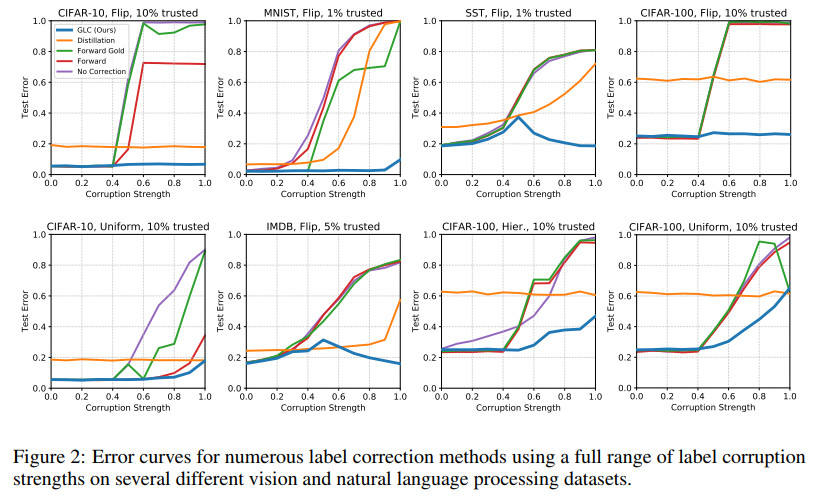
不同程度的可信标签在多个图像数据集上的效果对比如下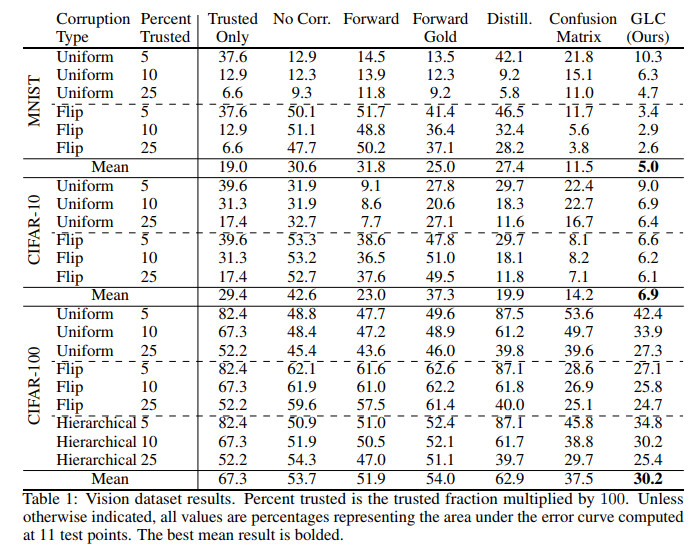
不同程度的可信标签在多个自然语言处理数据集上的效果对比如下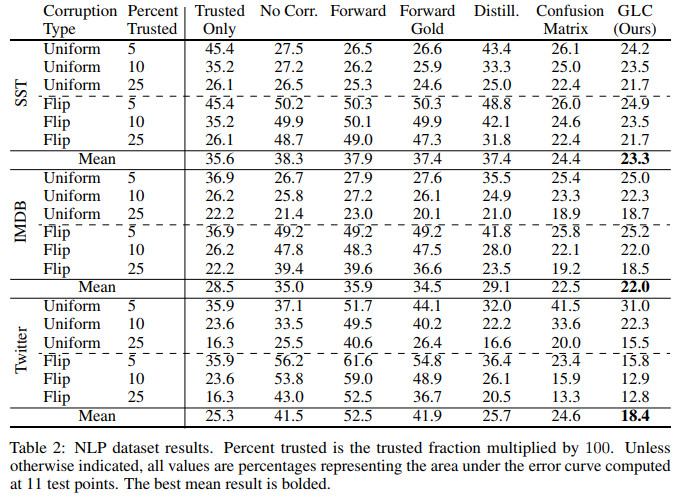
不同程度的可信标签效果对比如下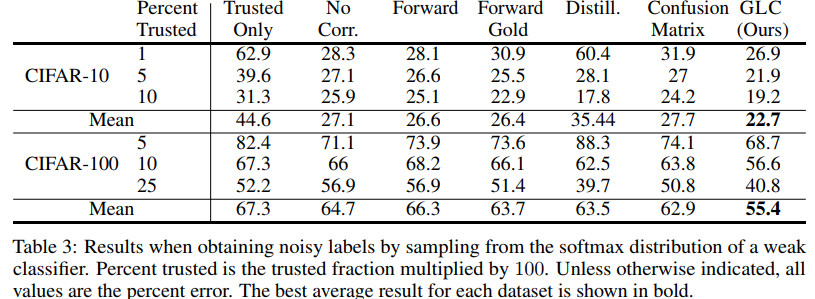
代码地址


文章评论